Akce
Specifikace požadavků¶
1. Minimální požadavky¶
- 1.1 Implementace datových pum
- 1.1.1 Aplikace musí obsahovat datové pumpy pro minimálně dva různé ALM nástroje, a to dle následujícího pořadí priorit:
- Jira + Git
- GitHub
- Redmine + GitLab
- Další ALM nástroje
- 1.1.2 Pokud pumpa potřebuje stáhnout repozitář lokálně, po dokončení dolování by se měl smazat.
- 1.1.3 Pumpa pro GitHub může být realizována spuštěním pumpy pro Git s následným doplněním potřebných dat.
- 1.1.4 Pumpy by měly umožňovat zakomponovat různé
project_instance(Redmine, GitLab) do již vydolovaného projektu- Tím se rozšíří sada lidí a identit (buďto se identity přiřadí k již existujícím lidem z vydolovaného
project_instance, nebo se vytvoří nové) - Dále to umožní propojení mezi ticketama a commity.
- Při přidávání nové instance projektu je nutné identifikovat propojující dotazy a propojit je se stávajícími daty.
- Nutné projet všechny commit messages již uložených instancí -> nutné udělat manuálně zpětně
- Při spojování 4 ALM dohromady, u přidávání posledního se projdou commit messages všech 3 předchozích
- např. Git nepodporuje zmiňování commitů mezi sebou, GitHub ano.
- Tím se rozšíří sada lidí a identit (buďto se identity přiřadí k již existujícím lidem z vydolovaného
- 1.1.5 Kvalitní implementace pump pro snadné rozšíření o další ALM nástroje.
- Vysoká úroveň abstrakce + využití rozhraní.
- 1.1.6 Aplikace by měla umět stáhnou prázdný projekt (nový repozitář bez souborů) tzv. zpracovat prázdný stav
- 1.1.1 Aplikace musí obsahovat datové pumpy pro minimálně dva různé ALM nástroje, a to dle následujícího pořadí priorit:
- 1.2 Mapování dat do systému SPADe
- 1.2.1 Data budou přenášena do databáze SPADe na základě definice poskytnuté zadavatelem.
- Tabulky databáze není možné jakkoliv upravovat.
- 1.2.2 Systém musí umět řešit možné kolize mapování sloupců mezi různými ALM nástroji.
- U nástrojů jako Git a GitHub může docházet k rozdílům v interpretaci tagů a release, přičemž ve SPADe ne každý tag nutně znamená release.
- V těchto případech se použijí defaultní hodnoty dle uvážení vývojového týmu.
- 1.2.3 Systém bude umožňovat sloučení více identit uživatele do jednoho člověka.
- 1.2.4 Systém musí umožnit mazání projektu a jeho znovu stažení bez duplicit či chyb.
- 1.2.1 Data budou přenášena do databáze SPADe na základě definice poskytnuté zadavatelem.
- 1.3 Grafické uživatelské rozhraní (GUI)
- 1.3.1 GUI umožní uživateli specifikovat repozitář a další parametry pro dolování dat z ALM nástrojů.
- 1.3.2 Autentizace a autorizace pro dolování soukromých projektů (přihlašovací formulář nebo API klíč).
- Údaje budou patřičně zabezpečeny.
- 1.3.3 Uživatel bude průběžně informován o stavu dolování dat, GUI nesmí "zamrznout".
- 1.3.4 Při probíhajícím těžení se zakáže pumpování dalšího projektu, tj. pumpy nemusí umět pracovat paralelně, pouze sekvenčně.
- 1.3.5 GUI bude napsáno v angličtině.
- 1.3.6 Před těžením se GUI zeptá, jestli bude těžit nový projekt nebo jestli bude přidávat data do existujícího projektu
- Implementace přes CheckBox (chci/nechci přidávat do exitujícího) + SelectBox (když chci, do jakého konkrétně)
- 1.3.7 GUI musí zobrazovat jasné chybové zprávy včetně návodu, jak chybu řešit
- 1.4 Pseudonymizace citlivých údajů
- 1.4.1 Aplikace bude umožňovat uložení citlivých údajů do databáze pod pseudonymizovaným názvem podle přepisovací tabulky.
- 1.4.2 Mezi citlivé údaje patří:
- Název projektu
- Popisky ticketů
- Autoři
- Commit messages
- Názvy artefaktů
- Obsah artefaktů (pouze plaintext, ne PDF/Word)
- 1.4.3 Aplikace na vyžádání vygeneruje přepisovací tabulku, která mapuje pseudonymizované texty na skutečné.
- Tabulka bude ve formátu XML nebo JSON.
- Podle této tabulky bude možné převést pseudonymizovaná data zpět do jejich původní podoby
- Dotahování nových dat musí s tabulkou také umět pracovat (např. přidání nového uživatele)
- 1.4.4 Na konci těžícího procesu si uživatel bude moci vybrat, jestli data (a které konkrétně) chce pseudonymizovat
- 1.4.5 Pro analýzy anti-patternů je u artefaktů důležité uchovat informaci o počtu znaků.
- V databázi není možné nahradit celý plaintext jedním číslem značící počet znaků.
- Místo konkrétního plaintextu může být do databáze uložen stejně dlouhý dummy text (Lorem Ipsum).
- Nutné důkladněji promyslet, současná databáze na pseudonymizaci obsahu artefaktů není stavěná.
- 1.5 Uživatelsky mapovaná data
- 1.5.1 Uživatel bude mít možnost změnit defaultní mapování údajů v MySQL databázi.
- 1.5.2 Místo dolování všech dat projektu z ALM si bude moci uživatel zvolit libovolnou podmnožinu sloupců k dolování (např. pouze commity, commity + issues, main branch).
- GUI by mělo obsahovat několik scénářů, podle kterých by uživatel mohl chtít dolovat data.
- 1.5.3 Uživatel bude moci specifikovat časové období, ze kterého chce data dolovat.
- Uživatel bude moci zvolit časové rozmezí na úrovni dnů, hodin a minut.
- Den bude povinný, hodiny a minuty nebudou povinné.
- Validní formáty:
- Od 19.2.2025 do 11.3.2025
- Od 19.2.2025 15:35 do 11.3.2025 10:40
- Pokud uživatel specifikuje pouze dny a v ALM bude několik záznamů k dolování, dolovat se bude vždy od nejstaršího záznamu (počátek) až po nejnovější záznam (konec).
- 1.5.4 Další rozšíření bude umožňovat dolování dat od posledního data pumpování a od konkrétního milníku (např. release).
- 1.6 CICD nasazení
- 1.6.1 Pumpy by měly být snadno nasaditelné s využitím CICD na GitLab.
- 1.6.2 Měla by být možnost připojení na vlastní reálnou databázi, nebo na databázi běžící v Dockeru.
- Na tuto reálnou databázi se následně mohou napojit i jiné nástroje (např. analyzátor anti-patternů)
2. Mimofunkční požadavky¶
- 2.1 Architektura projektu
- 2.1.1 Datové pumpy a GUI budou navrženy tak, aby je bylo možné implementovat nezávisle na sobě.
- Mezi pumpami a GUI bude využito API.
- Technologie pro backend a frontend jsou volitelné, přičemž po domluvě se použije SpringBoot pro backend a React pro frontend.
- 2.1.2 Systém musí používat databázi MySQL.
- 2.1.3 Pro snadnou přenositelnost projektu je vhodné využít kontejnerizaci (Docker nebo Podman).
- Cílové prostředí není specifikováno.
- Možnosti nasazení zahrnují lokální spuštění nebo server na CIV.
- 2.1.4 Projekt se bude skládat z následujících částí:
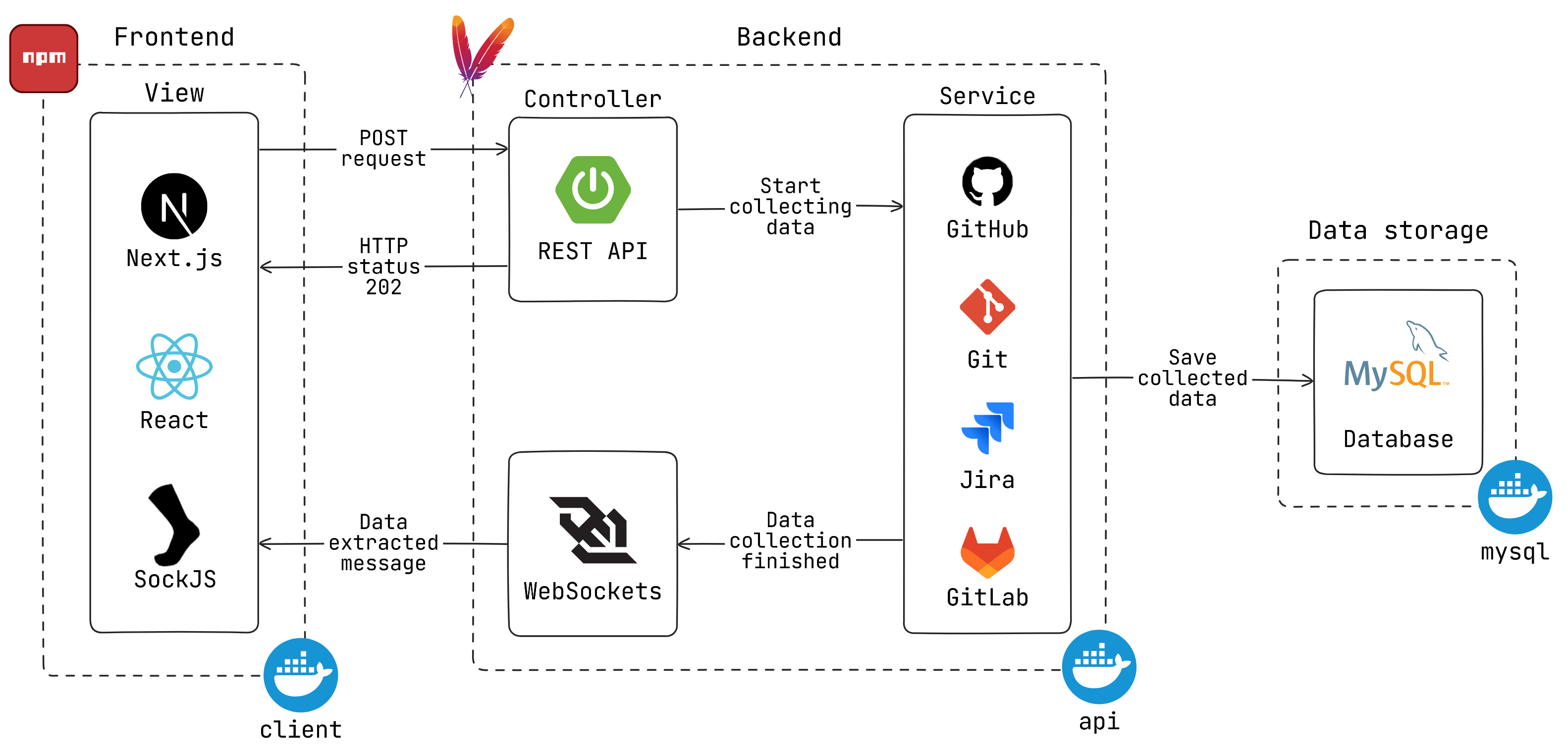
- 2.1.1 Datové pumpy a GUI budou navrženy tak, aby je bylo možné implementovat nezávisle na sobě.
- 2.2 Testování
- 2.2.1 Testování bude primárně zaměřeno na funkčnost datových pump a GUI bude testováno pouze okrajově.
- Zatím není blíže specifikováno, co a jak konkrétně bude třeba testovat.
- 2.2.2 Druhy testů:
- Jednotkové
- End-to-End
- Integrační
- 2.2.3 Kód bude testován staticky přes CICD pipeline na GitLab
- 2.2.1 Testování bude primárně zaměřeno na funkčnost datových pump a GUI bude testováno pouze okrajově.
- 2.3 Dokumentace
- 2.3.1 Nedílnou součástí projektu je dokumentace, která bude zahrnovat následující dokumenty:
- Programátorská dokumentace (popis kódu, architektura, možnosti rozšíření)
- Instalační manuál včetně nastavení prostředí (Docker, MySQL)
- Uživatelský manuál (popis práce s pumpami, vysvětlení GUI)
- Use case návody (konkrétní scénáře použití aplikace)
- README na repozitáři GitLab (základní informace o projektu)
- 2.3.2 Všechny zmíněné dokumenty budou psány v anglickém jazyce, protože se jedná o školní projekt s využitím na mezinárodní úrovni.
- 2.3.1 Nedílnou součástí projektu je dokumentace, která bude zahrnovat následující dokumenty:
- 2.4 Optimalizace rychlosti těžení (Výkonost)
- 2.4.1 V kódu musí být snaha optimalizovat rychlost těžení.
- 2.4.2 Na datové pumpy nejsou kladeny konkrétní požadavky na maximální dobu těžení.
- Hlavně z toho důvodu, že velikost a složitost dolovaných dat může být libovolná.
- 2.5 Spolehlivost
- 2.5.1 Na klientské straně bude zajištěna kontrola základních vstupů (např. validní URL, správný formát dat), aby se předešlo zbytečným pádům.
- 2.5.2 Pokud už probíhá těžení dat, GUI zabrání spuštění další pumpy (viz i funkční požadavek 1.3.4). To snižuje riziko nekonzistentních dat.
- 2.5.3 Aplikace bude ukládat základní chybové zprávy (např. selhání připojení k databázi, chybný vstup od uživatele) do textového souboru nebo konzole.???
- 2.6 Použitelnost GUI
- 2.6.1 GUI bude navrženo dle zásad UX, především: přehlednost, konzistence, minimalizace kognitivní zátěže, zpětná vazba na akce uživatele.
- 2.6.2 Součástí GUI bude interaktivní nápověda (tooltipy nebo help sekce) vysvětlující jednotlivé možnosti dolování.
- 2.6.3 Aplikace bude přístupná i pro uživatele bez hlubších technických znalostí (tzv. "non-technical users").
- 2.7 Podporovatelnost
- 2.7.1 Veškerý zdrojový kód musí obsahovat srozumitelné a konzistentní komentáře vysvětlující funkci jednotlivých částí, zejména pak u metod, tříd a logiky, která není na první pohled zřejmá.
- 2.7.2 Projekt bude rozdělen do přehledných složek, aby se v něm noví vývojáři snadno orientovali.
- 2.7.3 V repozitáři bude soubor README.md s minimalistickým popisem, jak aplikaci spustit lokálně.
- 2.7.4 Projekt bude verzován v prostředí GitLabu, včetně správy větví, merge requestů a tagů dle týmových konvencí. (Konvence)
3. Rozšiřující požadavky (TODO)¶
- 3.1 Grafické uživatelské rozhraní GUI
- 3.1.1 Uživatel bude mít možnost přepnout jazyk do češtiny.
- 3.1.2 V GUI bude možné zadat frontu repozitářů k sekvenčnímu dolování.
- 3.1.3 Při zadání URL root se zobrazí všechny projekty, které lze těžit.
- Např. když
url/projectsobsahuje projektyurl/projects/aswi2024aurl/projects/aswi2025, GUI nabídne těženíaswi2024aaswi2025
- Např. když
- 3.1.4 Zobrazení zbývajícího času těžení (zatím není zcela jasné, jak se určí).
- 3.1.5 Všechny akční tlačítka budou mít ikony + textové popisky (dle Material Design guidelines)
- 3.1.6 Barvy a rozměry komponent dle navrženého designu
- 3.1.7 Stejné umístění hlavní navigace na všech obrazovkách
- 3.1.8 Terminologie bude jednotná (např. vždy "těžení" namísto střídání "těžení/dolování")
- 3.1.9 Po dokončení těžby se zobrazí souhrn:
- Počet získaných záznamů (commity/tickety)
- Varování o případných problémech (např. "Nepodařilo se načíst 12 commitů")
- 3.1.10 Responzivní design
- 3.1.11 Tmavý/světlý režim
MoSCoW (pro TSP1)¶
M - Must have¶
- 1.1.1 Podpora minimálně dvou ALM nástrojů (Jira + Git nebo GitHub)
- 1.1.2 Mazání lokálního repozitáře po dokončení těžby
- 1.2.1 Přesné mapování podle zadané databázové struktury
- 1.2.2 Řešení rozdílů v interpretaci v ALM nástrojích, které se mapují na tabulky SPADe
- 1.2.4 Mazaní a znovu stažení projektu
- 1.3.5 GUI bude napsáno v angličtině
- 1.3.6 Volba v GUI mezi dolováním nového projektu nebo rozšíření existujícího (CheckBox/SelectBox)
- 2.1.1 Nezávislost implementace pump a GUI (API komunikace)
- 2.1.2 Systém musí používat databázi MySQL
- 2.1.3 Kontejnerizace (Docker/Podman)
- 2.1.4 Dodržování definované struktury projektu
- 2.3.1 Kompletní dokumentace (vývojářská, instalační, uživatelská)
- 2.3.2 Všechny dokumenty z 2.3.1 v angličtině
- 2.7.4 Verzování projektu
S - Should have¶
- 1.1.4 Pumpy by měly umožňovat zakomponovat různé
project_instance(Redmine, GitLab) do již vydolovaného projektu - 1.1.5 Snadné rozšíření o další ALM nástroje
- 1.1.6 Zpracování prázdného projektu
- 1.2.3 Slučování více identit uživatele
- 1.3.2 Autentizace a autorizace pro dolování soukromých projektů (API klíč)
- 1.3.3 Průběžné informování o stavu těžby
- 1.3.4/2.5.2 Sekvenční těžba (zakázat paralelní běh v GUI)
- 1.3.7 GUI zobrazuje jasné chybové zprávy
- 1.6.1 CI/CD nasazení na GitLabu
- 1.6.2 Podpora Dockeru a externí DB
- 2.5.1 Kontrola základních vstupů, aby se předešlo zbytečným pádům
- 2.6.1 GUI bude navrženo dle zásad UX
- 2.7.1 Zdrojový kód bude řádně okomentovaný
- 2.7.2 Projekt bude strukturován do přehledných složek pro snadnou orientaci
C - Could have¶
- 1.1.3 GitHub pumpa jako rozšíření Git pumpy
- 1.5.3 Možnost omezit těžbu na časové období
- 2.2.1 Testování pump
- 2.2.2 Jednotkové, integrační a E2E testy
- 2.2.3 Statická analýza kódu v CI/CD
- 2.4.1 Optimalizace rychlosti těžby
- 2.5.3 Aplikace bude ukládat základní chybové zprávy
- 2.6.2 GUI bude mít interaktivní nápovědy (tooltipy nebo help sekce)
- 2.6.3 GUI bude přístupné i pro netechnické uživatele
- 2.7.3 Vytvoření README.md
- 3.1.1 Česká lokalizace GUI
- 3.1.2 Fronta repozitářů pro sekvenční těžbu
- 3.1.3 Zobrazení všech dostupných projektů z URL
- 3.1.5 Všechny akční tlačítka budou mít ikony + textové popisky
- 3.1.6 Barvy a rozměry komponent dle navrženého designu
- 3.1.7 Stejné umístění hlavní navigace na všech obrazovkách
- 3.1.8 Terminologie bude jednotná
- 3.1.9 Po dokončení těžby se zobrazí souhrn
- 3.1.10 Responzivní design
- 3.1.11 Tmavý/světlý režim
W - Will not have¶
- 1.3.1 Možnost zadat repozitář a parametry těžby
- 1.4.1 Ukládání citlivých dat pod pseudonymy
- 1.4.2 Pseudonymizace: názvů projektů, popisků, autorů, commit zpráv, artefaktů
- 1.4.3 Generování převodní tabulky (XML/JSON)
- 1.4.4 Volba pseudonymizace na konci těžby
- 1.4.5 Zachování délky textu u pseudonymizovaných artefaktů
- 1.5.1 Možnost změnit výchozí mapování dat
- 1.5.2 Výběr podmnožiny dat k těžbě (např. jen commity)
- 1.5.4 Těžba od posledního data/milníku
- 2.4.2 Žádné striktní limity na dobu těžby
- 3.1.4 Zobrazení zbývajícího času těžení (zatím není zcela jasné, jak se určí)
Autor: Štěpán Faragula + Jakub Homolka
Datum: 23.4.2025
Stav: hotový
Aktualizováno uživatelem Jakub Homolka před asi 3 hodin(y) · 69 revizí