DatasetProcessing » Historie » Revize 9
« Předchozí |
Revize 9/10
(rozdíl)
| Další »
Petr Hlaváč, 2020-05-27 10:03
DatasetProcessing¶
Složka obsahuje implementace processoru pro jednotlivé datasety. Processory jsou dynamicky importovány je tedy proto nutné dodržet pojemnování "dataset-name"_processor.py.
Připravený date_dic naplně následovně
date_dict klíč -> datum ve formát YYYY-mm-dd-hh
date_dict hodnota -> data_dict (další dictionary)
data_dict klíč -> název zařízení
data_dict hodnota -> CSVUtils.CSVDataline
při tvorbě CSVUtils.CSVDataline probíhá kontrola validity dat.
při exportu dat do CSV se následně kontroluje jestli objekty jsou opravdu ze třídy CSVUtils.csv_data_line!!
Po implementování metody je nutné změnit Return None na Return date_dict
Generovaný Processor¶
from Utilities.CSV import csv_data_line
def process_file(filename):
"""
Method that take path to crawled file and outputs date dictionary:
Date dictionary is a dictionary where keys are dates in format YYYY-mm-dd-hh (2018-04-08-15)
and value is dictionary where keys are devices (specified in configuration file)
and value is CSVDataLine.csv_data_line with device,date and occurrence
Args:
filename: name of processed file
Returns:
None if not implemented
date_dict when implemented
"""
date_dict = dict()
#with open(filename, "r") as file:
print("You must implements process_file method first!")
return None
Vzorově implementovaný processor¶
Struktura open dat koloběžek ve staženém csv je "22.08.2018 12:27:00";"stojan-Machovka";210;1 "DATUM";"JMENO_STOJANU";"CISLO_KONKRETNÍHO_STOJANU";"STAV".
Potřebná data pro zobrazení v mapě jsou specifikovány v Utilities.CSVUtils.csv_data_line a jsou to název, datum (YYYY-dd-mm-hh) a četnost
Processor tedy postupuje následovně
- Otevře soubor a čte ho po řádcích
- Rozdělí si data z řádky po sloupcích splitem se separátorem (;)
- Na první pozici máme datum ten převedeme na požadovaný formát funkcí implementovanou v Utilities.date_formating.py
- Jako název devicu zvolíme název stojanu tedy druhý sloupec"
- Četnost je inkrementována na základě počtu záznamu v dané hodině.
Když už máme všechny potřebná data vytvoříme si slovník, kde klíčem bude datum a hodnotou další slovník,
kde klíčem je název zařízení a hodnotou objekt třídy z Utilities.CSVUtils.csv_data_line.
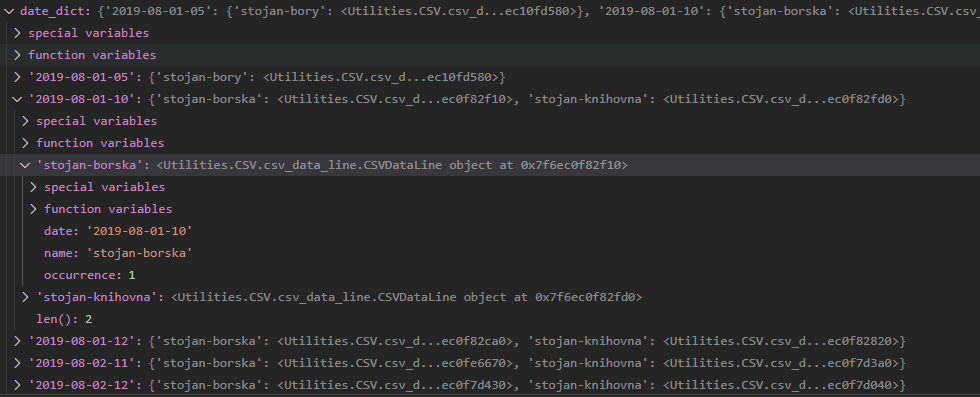
Ukázka výstupního slovníku
V této ukázce je vidět validní výstupní slovník.¶
Kód¶
from Utilities.CSV import csv_data_line
from Utilities import date_formating
def process_file(filename):
"""
Method that take path to crawled file and outputs date dictionary:
Date dictionary is a dictionary where keys are dates in format YYYY-mm-dd-hh (2018-04-08-15)
and value is dictionary where keys are devices (specified in configuration file)
and value is CSVDataLine.csv_data_line with device,date and occurrence
Args:
filename: name of processed file
Returns:
None if not implemented
date_dict when implemented
"""
date_dict = dict()
with open(filename, "r") as file:
for line in file:
array = line.split(";")
date = date_formating.date_time_formatter(array[0][1:-1])
name = array[1][1:-1]
if date not in date_dict:
date_dict[date] = dict()
if name in date_dict[date]:
date_dict[date][name].occurrence += 1
else:
date_dict[date][name] = csv_data_line.CSVDataLine(name, date, 1)
return date_dict
Aktualizováno uživatelem Petr Hlaváč před téměř 5 roky(ů) · 9 revizí